JavaScript工作原理
JavaScript 如何被编译
计算机里偏向硬件的语言称为低级语言,我们可以直接通过低级编程语言来控制硬件行为。
而把偏向人类的,也就是人类更容易理解的语言称为高级语言,我们可以使用高级语言来间接控制硬件的行为。
最低级的语言就是机器语言,最高级的语言就是人类的语言。我们使用大脑将人类语言翻译成编程语言。
越高级的语言越简单抽象更方便读和写,但执行效率差。
高级语言需要逐步转换成更低级的语言才能被硬件使用。
越高级,中间的转换时间越长,效率越低。
越低级的语言执行速度越快但是由于缺少高级语言的便捷的语法特性,所以很难编写代码,并且编写的代码更加危险容易出错。
比如:很难做内存管理,经常导致内存泄漏并且很难追踪、解决问题。
同时低级语言很难兼容众多的CPU平台。
所以为了解决这些问题,越来越多的高级语言被开发出来。但无论你多么高级,为了让机器可以使用都必须编译成低级语言。
JavaScript 就是高级语言,它由Brenddan Eich花费天发明出来。
最初设计是借鉴了C语言的基本语法、Java语言的数据类型和内存管理、Schema语言将函数提升到“第一公民”的地位、Self语言,使用了基于原型prototype的继承机制。
所以JavaScript实际上是 函数式编程+面向对象编程 这两种语言风格的缝合怪。
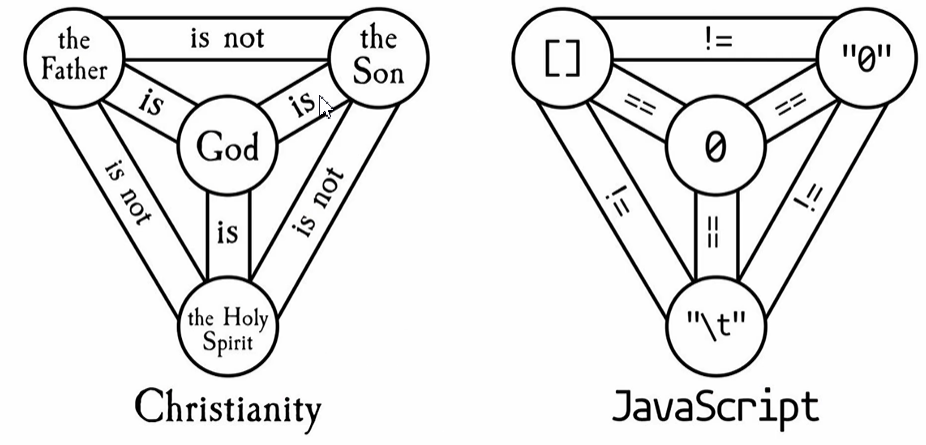
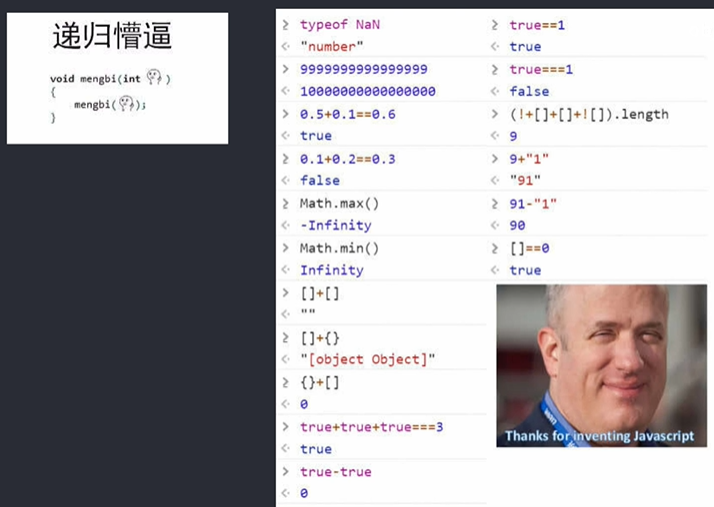
也正是因为最初设计时的不严谨导致后来的历史遗留问题:
(‘b'+'a'+ +'a'+'a').toLowerCase(); |
0 == “0” |
JS是动态类型语言,它与C++相比,它定义变量不需要关心他的数据类型,但对于C++这种静态类型语言,不仅需要声明类型还需要赋予正确的值。
对于复杂的应用类型,在JavaScript里,我们可以在声明赋值之后,可以随意添加、删除里面的属性。
这对于编译器来说是个灾难,因为源代码里提供的信息太少了,JS的语言特性让我们没有办法在运行前知道变量的类型,只有在运行期间(runtime)才能确定各个变量的类型,这又导致了JS无法在运行前编译出更加迅速的低级语言代码也就是机器代码(Machine Code)。
相反使用C++编程时,你会提供足够的类型信息来帮助编译器编译出机器代码。
所以C++并不是故意设计的这么难,而是为了更高效的编译。
JS虽然是动态语言,它执行起来依然很快,尤其是启动时.
比如node运行一段代码,几乎是瞬间完成的。
这是因为现代的JS引擎都使用了一项技术,叫Just-In-Time Compilation(运行时编译),简称JIT。
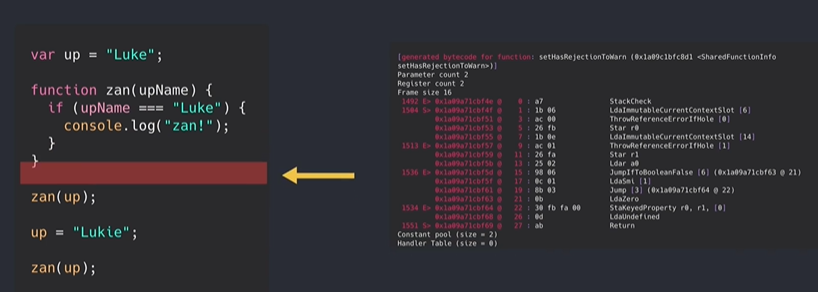
JIT就是运行阶段生成机器代码,而不是提前生成,JIT把代码的运行和生成机器代码是结合在一起的。
在运行阶段收集类型信息然后根据这些信息编译,生成机器码之后,再运行这些代码时就是使用生产好的机器代码。
还有另外一种方式叫AOT(Ahead Of Time),在运行前提前生成好机器代码,比如像C++这样的语言。
既然JS是一门高级语言,他被计算机CPU执行前需要通过某种程序,将JS转换成低级的机器语言并执行。
这种程序被称作为JavaScript引擎,和其他语言相比JavaScript有许多执行引擎。
比如 谷歌chrome使用的V8引擎,Webkit使用的JavaScriptCore,Mozilla的SpiderMonkey,QuickJS和Facebook、React Native中使用到Hermes。
但这些引擎在编译JS时大致的流程差不多。

首先将JS源码通过解析器parser(解析器) 解析成抽象语法处AST。
接着在通过解释器,将AST编译成字节码bytecode,字节码是跨平台的一种中间表示。不同于最终的机器代码,字节码与平台无关,能够在不同操作系统上运行。
字节码最后通过编译器生成机器代码,由于不同的处理器平台使用的机器代码会有差异,所以编译器会根据当前平台来编译出相应的机器代码,这里的机器代码,其实就是汇编代码。
以上其实是简化的流程,在不同JS引擎中表现会有一定的差异。
比如在V8引擎5.9版本之前,是直接把AST生成,得机器代码,他是不会额外生成bytecode字节码。
但在之后的版本,V8使用了新的架构,则会生成bytecode。
V8引擎的原理
chrome浏览器运行JS的引擎是V8。
Nodejs的运行时环境是V8引擎。
electron的底层引擎也是V8。
JS之所以可以再不同环境上运行就是因为V8。
什么是V8引擎
V8引擎是指V型8气缸发动机,他一般使用在中高端汽车上
V8是用C++编写的,谷歌开源高性能JavaScript和WebAssembly引擎。
是一个接受JavaScript代码,编译JS代码然后执行的C++程序。
编译后的代码可以再多种操作系统,多种处理器上运行。
V8要负责以下工作:编译和执行JS代码、处理器调用栈、内存的分配、垃圾的回收。
V8引擎曾在17年做了一次大的架构调整
早期V8编译和执行代码
一般来说,大部分JS引擎在编译和执行代码都会用到三个重要的组件,分别是解析器(parser)、解释器(interpreter)和编译器(compiler)。
**解析器(parser)**负责将JS源代码解析成抽象语法树AST。
**解释器(interpreter)**负责将AST解释成字节码bytecode,同时解释器也有直接解释执行bytecode的能力。
**编译器(compiler)**负责编译出运行更加高效的机器代码。
但在V8早期5.9版本之前,V8引擎没有解释器,却有两个编译器。
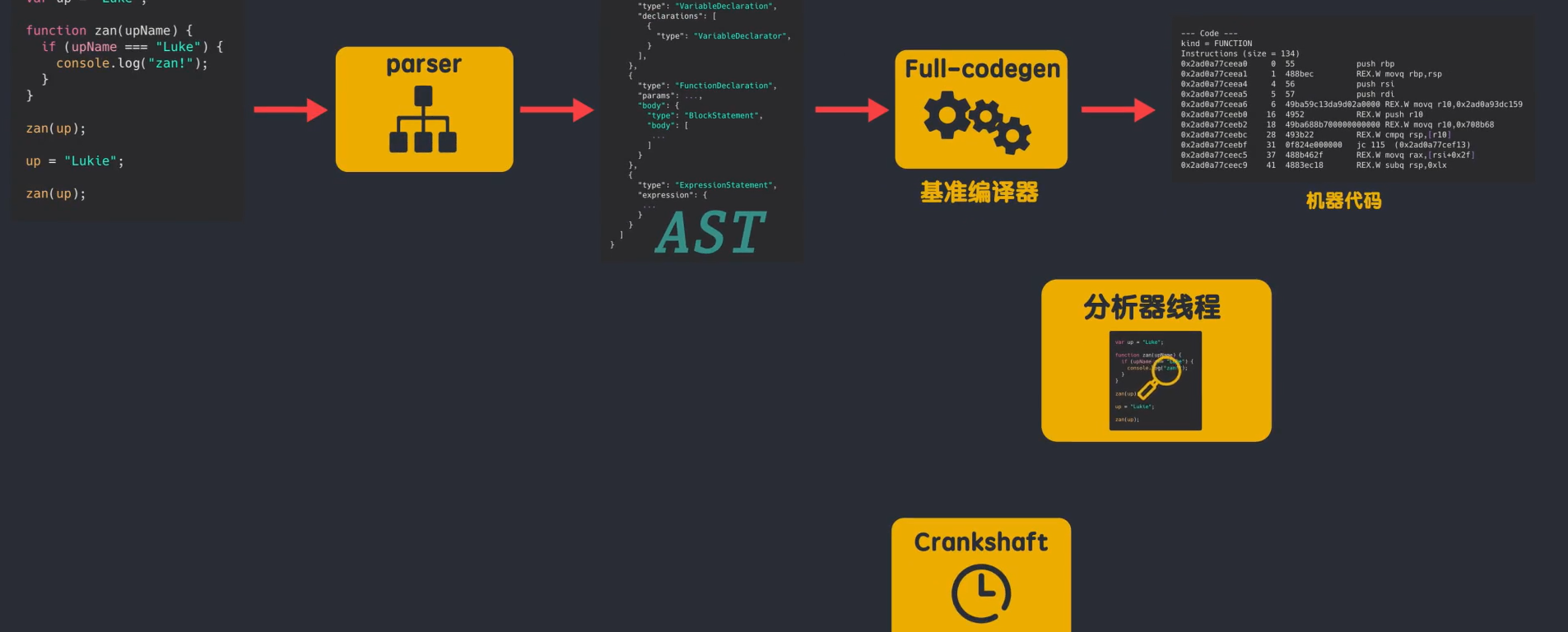
他的编译流程是:JS由解析器(parser)解析后生成AST,然后由Full-codegen编译器直接使用AST来编译出机器代码,而不进行任何中间转换,Full-codegen编译器也被称为基准编译器,由它生成的是一个基准的、未被优化的机器代码。
这样做的好处就是当你第一次执行JS时,就是直接使用了高效的机器代码。
因为没有中间的字节码产生,所以就不需要解释器,当代码运行一段时间后。V8引擎中的分析线程收集了足够的数据来帮助另一个编译器Crankshaft来做代码优化。
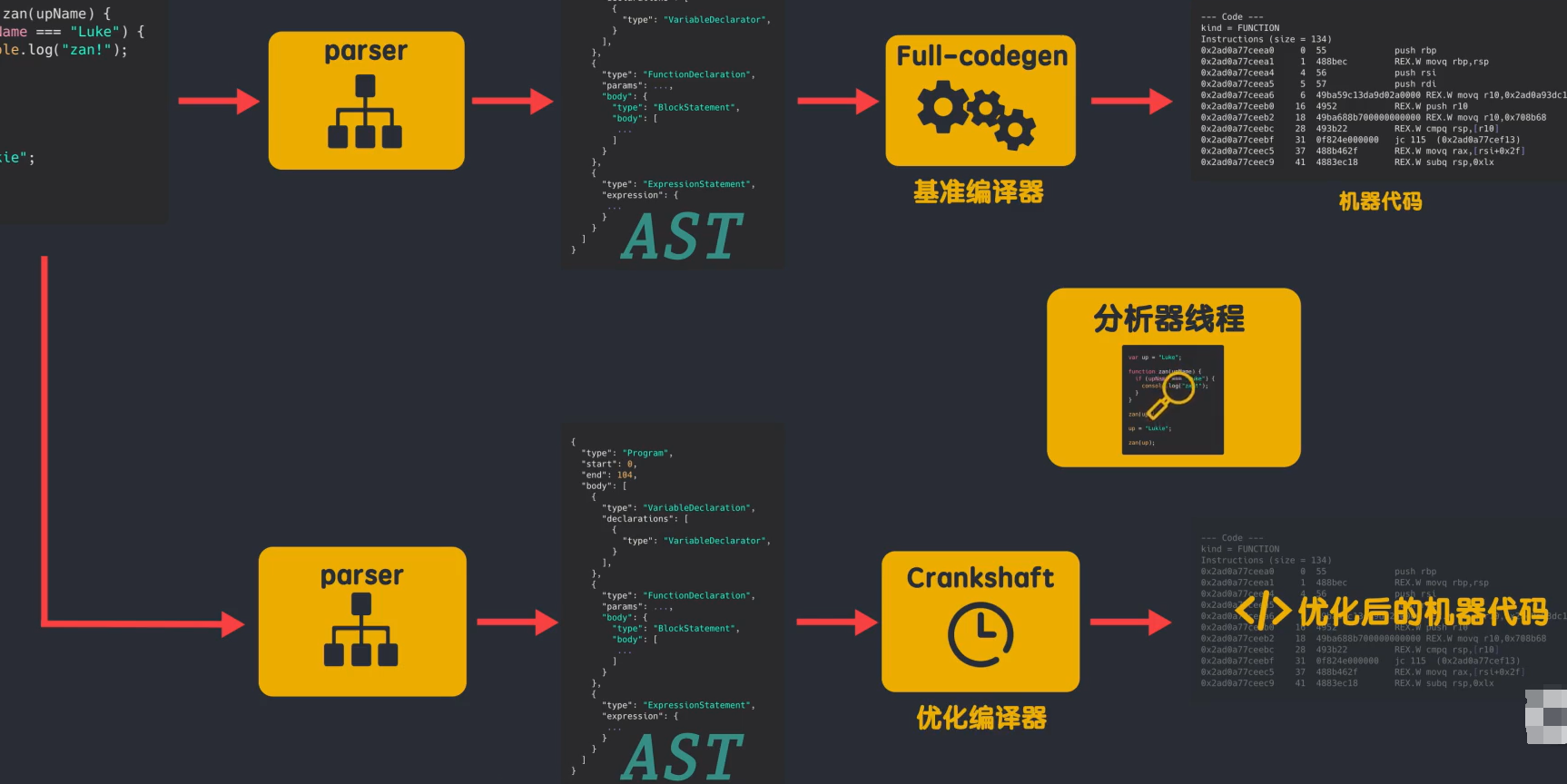
根据分析线程的结果,解析器把需要优化的代码重新解析生成AST,再由Crankshaft使用生成好的AST生成优化后的机器代码,来提升运行的一个效率。
所以crankshaft的编译器,又被称为优化编译器。
这样设计的初衷是好的,减少了AST到字节码的转换时间,提高外部浏览器中JS的执行的性能。
但是这样的架构设计,也带来了不少问题。在V8团队的官方博客的这篇文章中,提到了一些之前的架构问题。
大致只有三点:
- 第一个是生成的机器码会占用大量的内存,这对于打内存的电脑还好说,但对于早期的安卓低内存的设备基本是不能承受的,并且有些代码仅仅执行一次,没有必要直接生成机器码。
- 第二个是缺少中间层的字节码,很多性能优化策略无法实施,导致V8引擎性能提升缓慢。
- 第三个是之前的编译器无法很好地支持和优化JS的新语法特性。
所以为了解决以上问题,V8团队用了三年半开发了一套新的V8架构,对于这个架构,V8团队有很高的赞誉、
它代表了V8团队通过测量实际JS性能并仔细研究Full-codegen和Crankshaft的缺点后收集到的共同见解的顶峰。
新架构: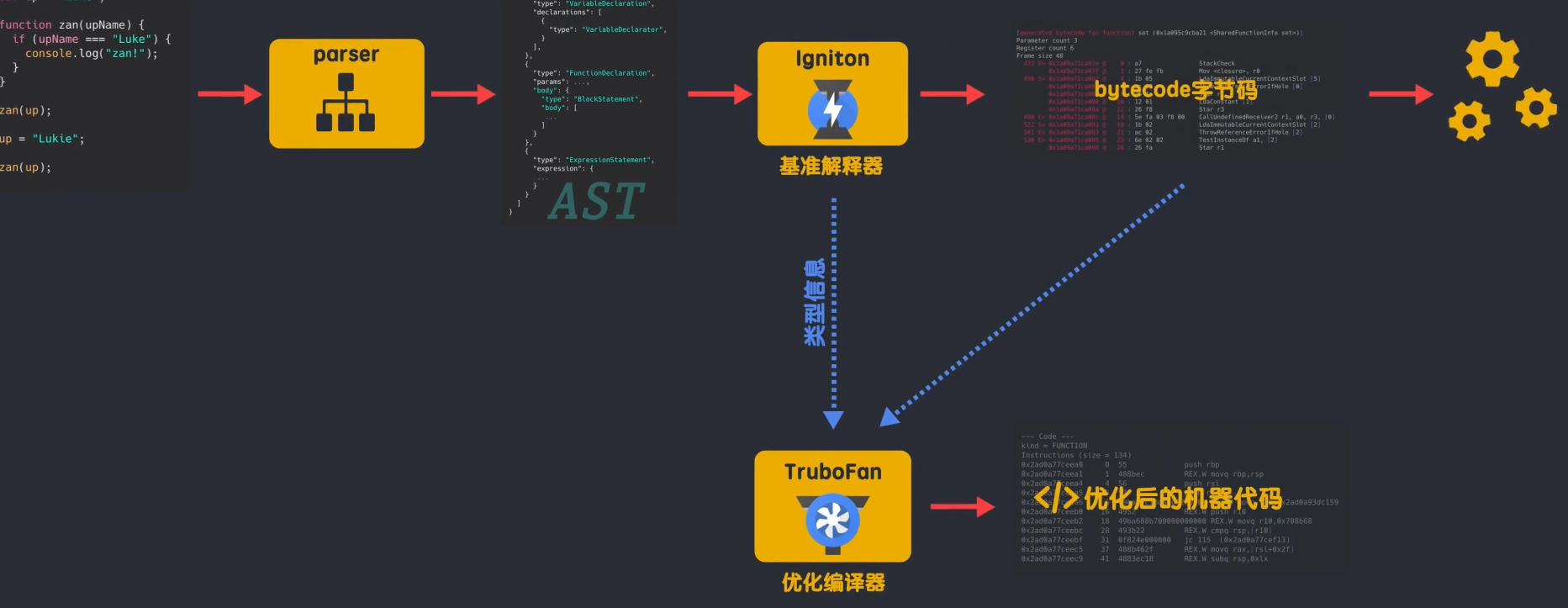
语法树的解析还是和基本保持一样,但在获得AST后V8引擎加入了解释器lgnition,语法树通过解释器lgnition生成了bytecode,此时AST被清除了,释放内存空间,生成的bytecode直接被解释器执行,同时生成的bytecode将作为基准执行模型,字节码更加简洁,生成的bytecode大小相当于等效的基准机器代码额20%到50%左右。
在代码的不断的运行过程中,解释器收集到了很多可以用来优化代码的信息。
比如变量的类型、哪些函数执行的频率较高,这些信息被发送给编译器(TurboFan),V8引擎新的编译器TurboFan会根据这些信息和字节码来编译出经过优化的机器代码。
V8引擎在处理JS过程中的一些优化策略:
- 如果函数只是声明,但未被调用,则不会被解析生成AST。(也就不会生成字节码)
- 函数只被调用一次,则lgnition生成bytecode后直接被解释执行。(TurboFan不会进行优化编译,因为它需要lgnition收集函数执行时的类型信息,这就要求函数至少执行大于一次。Turbofan才能够优化编译)
- 函数被调用多次,可能会被识别为热点函数。当lgnition解释器收集的类型信息确定后,这时的TurboFan则会将bytecode编译为优化后的机器代码以提高代码的执行性能,之后执行这个函数时就直接运行优化后的机器代码。
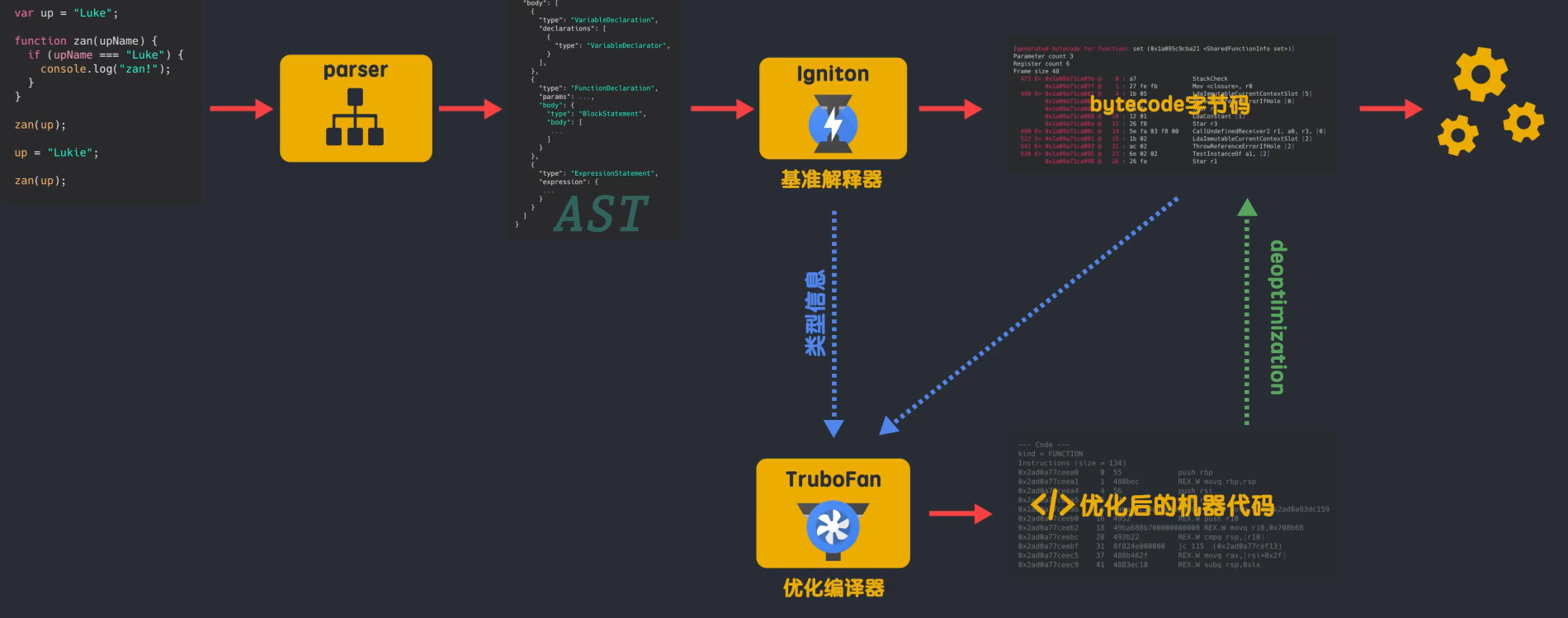
所以整体来说,就是出于一个运行字节码和优化的机器代码共存的一个状态,随着JS源码不断的被执行会有更多的源码被标记为热点代码,就会产生更多的机器代码。
但在某些情况下优化后的机器代码可能会被逆向还原成字节码,这个过程叫做deoptimization。这是因为JS是一个动态语言,会导致一个lgnition收集到的信息是错误的。
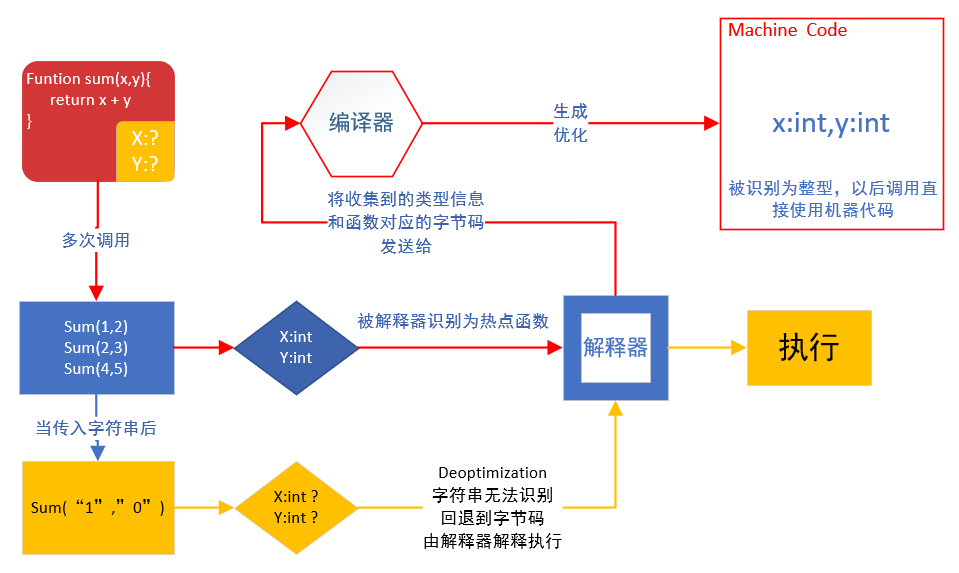
例子:
有一个sum函数,在函数声明时JS引擎并不知道参数x,y是什么类型,但在后面的多次调用中传入的x,y都是整型,sum函数被识别为热点函数。
解释器将收集到的类型信息和该函数对应的字节码发送给编译器,于是编译器生成的优化后的机器代码中,就假定了sum函数的参数x,y都是整型,之后遇到的该函数的调用就直接使用了运行更快的机器代码。
如果你此时调用sum函数传入了字符串,机器代码不知道如何处理字符串的参数,于是就需要进行deoptimzation,也就是回退到字节码,由解释器来解释执行。
所以说,偶们尽量不要把一个变量类型变来变去,对传入函数的参数的类型也是最好保持固定,否则会给V8引擎带来一些影响,损失一定的性能。
以上三点优化策略带来了一些好处。
- 由于不需要一开始直接编译成机器码,而是生成了中间层的字节码 ,字节码的生成速度是远远大于机器码的,所以网页初始化解析执行JS的时间缩短了,网页就可以更快的onload。
- 在生成的优化机器代码时,不需要从源码重新编译,而是使用字节码,并且当需要deoptimization时 ,只需要回归到中间层的字节码解释执行就可以了。
新的架构的确在性能上带来了很大的提升,并且功能模块的职能也更加清晰了,为未来JS的新功能和优化打下了结实的道路.
时间循环和异步回调
计算机里有两个重要的概念,栈和队列。
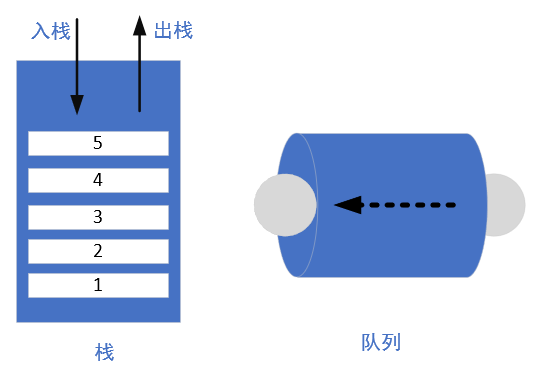
栈/堆栈:先进后出,后进先出
队列:先进先出,后进后出
调用栈是JS引擎追踪函数执行流程的一种机制,当执行环境中调用了多个函数时,通过这种机制,我们能够追踪到哪个函数正在执行,执行的函数体又调用了哪个函数。
它采用先进后出的机制来管理函数的执行。
举个例子,比如像这样一段函数:
function sum(a,b){ |
从调用栈的角度看,如何管理函数执行顺序?
首先函数的声明是不会放入栈中的。而调用栈,是被调用的函数才会入栈。
所以代码运行到第十行,average函数被调用,才会入栈。
流程:
发现average函数,把average的执行添加到调用栈(入栈),然后执行average函数体中的所有代码,当进入average函数体中执行第一行代码时,发现调用了sum函数,接着将sum函数入栈,执行sum函数体中的代码,直到sum函数执行完毕,然后继续执行sum函数后面的代码。
接着sum函数出栈,从栈顶移除,然后到average函数体中的代码全部执行完毕,返回到之前调用average的代码执行(11行),继续执行剩下的JS代码,average出栈。
最后执行的第11行,console.log()入栈,执行完, console.log()出栈。
此时,调用栈清空,也就是当前JS执行环境处于空闲状态 。
实际项目中,调用栈会比这个复杂的多,主要是因为调用层级比较深,会出现A调B,B调C,C调D,会有一个很长的调用链。
我们可以通过编辑器或者浏览器来查看某一行代码所处的一个调用栈环境。
常见的两种方法:
- 打断点,通过打断点你可以在控制台的调用栈窗口去查看当前具体的调用栈信息。
- 抛出异常,通过在函数体外抛出异常,你可以在控制台里去查看当前抛出异常的那行代码所处的一个调用栈环境。
我们在写代码的时候有时候会出现堆栈溢出的情况,比如常见的一个触发场景——递归。
当你使用递归时,却没有一个递归结束的判断时,调用栈就会被不断推入递归的函数,然后就会超出调用栈的一个堆栈限制,同时控制台会报错,告诉你当前调用栈已超出最大范围整个网页就会卡死。
这时考虑另外一个问题,JS的执行环境是一个单线程,这也就意味着JS环境只有一个调用栈,如果调用栈中的某个函数执行需要花费大量时间,因为只有一个调用栈就会导致调用栈被阻塞,无法入栈和出栈。
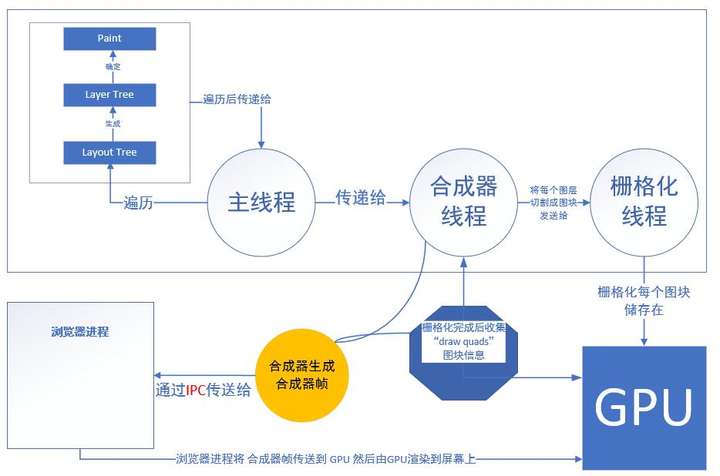
在《浏览器工作原理》里面提到,页面的布局绘制和JS执行都在一个主线程里,如JS执行迟迟不归还主线程的话就会影响页面的渲染,就可能导致页面出现卡顿的现象,也就严重影响用户的体验优化。
这个问题的一个优化方案就是使用事件循环和异步回调。
(待续)
内存管理和垃圾收集GC (坑位)